
大數據和Hadoop簡介
數據每天都呈指數級增長,隨著數據的增長,需要利用這些數據。和以前一樣,我們過去用軟驅來存儲數據,數據傳輸也很慢,但現在,這些都不夠了,云存儲被使用,因為我們有TB的數據。當今世界,社交媒體對數據增長的貢獻最大。它包括人們的行為、心態和其他幾個方面。據說每分鐘有300小時的視頻上傳到YouTube上,超過2000萬張照片上傳到Facebook和其他許多網站上。此外,上傳的數據沒有適當的結構,這是處理這些數據的最大挑戰。
隨著海量數據的高速生成,傳統的RDBMS系統無法處理如此快速的增長。此外,它們也無法處理非結構化數據。處理如此大量快速增長的異構數據并以高速處理這些數據變得非常困難。因此,需要這樣一個能夠高效處理大型數據集的系統。因此,為了解決這個問題,Hadoop應運而生。HDFS是Hadoop的組件,通過使用分布式存儲解決了大型數據集的存儲問題,而YARN則是解決處理問題的組件,大大縮短了處理時間。
Hadoop、數據科學、統計和;其他
Hadoop是一個開源軟件框架,用于使用分布式大型商用硬件集群存儲和處理大數據集。它由Doug Cutting和Michael J.Cavarella開發,并在Apache下獲得許可。它是用Java編寫的,是基于Google在MapReduce系統上寫的論文開發的,它應用了函數式編程的概念。它可靠、經濟、靈活、可擴展。
Hadoop的核心組件
核心組件如下所示
HDFS
HDFS或Hadoop分布式文件系統有Namenode和data node。Namenode是運行主守護進程的主節點,它管理數據節點并跟蹤所有操作。數據節點是實際存儲數據的從屬節點。
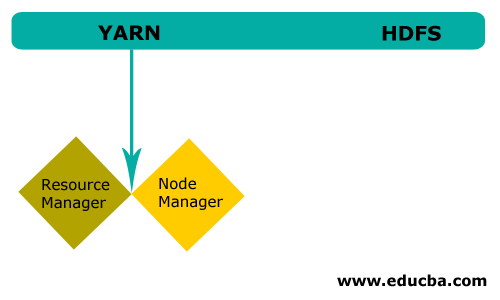
紗線
紗線由兩個主要成分組成:
1。ResourceManager:它在主節點上運行,管理所有資源,并調度所有應用程序。它有調度器&;應用程序管理器。
2。NodeManager:它在每個從屬節點上運行,負責管理容器和監控資源利用率。
這類熱門課程
Hadoop的幾個組件
有幾個組件,如豬、蜂巢、sqoop、水槽、mahout、oozie、zookeeper、HBase等。
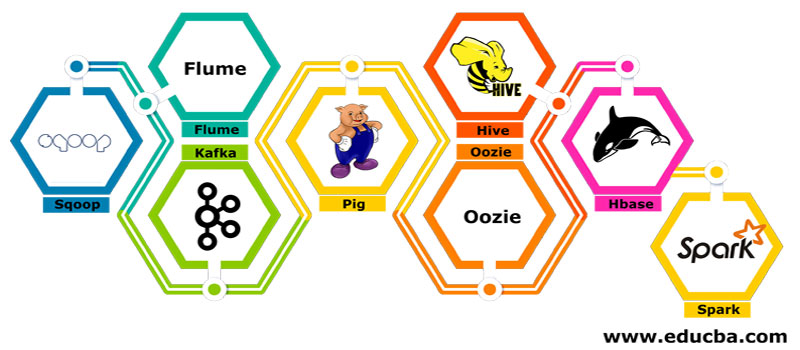
- Sqoop–它用于將數據從RDBMS導入和導出到Hadoop,反之亦然</李>
- Flume–它用于將實時數據拉入Hadoop</李>
- 卡夫卡–這是一個用于路由實時數據的消息傳遞系統</李>
- Pig–它被用作數據處理的腳本語言</李>
- Hive–它是一個基于HDFS的數據倉庫框架,讓熟悉SQL的用戶可以執行查詢以獲取數據。這些查詢稱為HiveQL</李>
- Oozie–它用于安排作業的工作流在指定的事件或時間上運行</李>
- Hbase–它是作為Apache Hadoop的一部分提供的無SQL數據庫</李>
- Spark–它用于執行內存處理,比Hadoop map reduce快得多</李>
Hadoop提供者
有很多公司提供Hadoop發行版。
以下是幾個最好的供應商:
- 克勞德拉
- 霍頓工廠
- MapR
學習Hadoop有幾個先決條件。有Java和腳本語言經驗者優先。盡管它已經有了自己的高級編程語言,比如pig和hive,它們可以生成后端代碼以供進一步處理,但仍然可以用Ruby、Python、Perl甚至C編程等任何編程語言創建自己的map reduce程序。
Bigdata和Hadoop在當今市場上的需求量很大。在接下來的幾天里,這將增加更多。很多組織已經開始使用Hadoop,而那些沒有使用Hadoop的組織將很快開始使用Hadoop。目前有一份報告稱,大公司已經開始投資大數據分析。大數據營銷預測總是處于上升趨勢,而且根本不是一種短命狀態。除此之外,與其他技術相比,Hadoop和大數據領域的工作總是提供高薪。
頂級大數據和Hadoop公司
以下是雇傭人數最多的幾家頂級公司:
- 領英
- 雅虎
- 亞馬遜
- 蘇格蘭皇家銀行
- 英國航空公司
- Expedia
- 沃爾瑪
很多公司都在使用大數據應用程序。這些是:
諾基亞
它使用Cloudera和Hadoop組件,比如應用程序的HDFS、HBase、Sqoop和Scribe。它有效地使用用戶數據來理解和改善用戶體驗。它使用數據處理和復雜分析來構建具有預測交通和分層高程模型的地圖。
SAS
它與Hadoop合作,通過提供一個提供視覺和交互體驗的環境,幫助數據科學家獲得更好的洞察力,從而幫助探索新趨勢。分析程序從數據中提取有意義的見解,內存技術有助于更快地訪問數據。
還有很多其他公司使用大數據平臺進行各種分析。這些是航空業黑匣子的飛行數據分析,股票市場的差異分析,等等。
Hadoop的優勢
以下是Hadoop的一些優點:
- 可擴展性–與傳統的RDBMS不同,它是一個高度可擴展的平臺,因為它可以在并行運行的商品硬件上以分布式集群存儲大型數據集</李>
- 經濟高效——對于RDBMS來說,存儲數據的成本太高,而Hadoop已經減輕了這一成本</李>
- 快速靈活——它通過分布式文件系統提供快速訪問數據的功能。它還提供從半結構化和非結構化數據中獲取業務見解的功能</李>
- 容錯——每當任何數據被發送到一個節點時,相同的數據都會被復制到其他節點,在第一個節點出現故障時可以訪問這些節點</李>
總結——什么是大數據和Hadoop
數據在不斷增長,因此總是需要大數據和Hadoop來利用這些數據。因此,具備Hadoop技能的專業人士在未來幾天內總能找到大量機會,并且可以成為推動企業發展和職業生涯的重要資產。
推薦文章
這是關于什么是大數據和Hadoop的指南。這里我們討論了大數據和Hadoop的基本概念和組件。您還可以閱讀以下文章了解更多信息——











